-
 Nathan Hertz authoredNathan Hertz authored
Nathan Hertz authoredNathan Hertz authored
Workspace Architecture: Overview
Introduction
A key ingredient in the initiative to deliver science-ready data products is a mechanism to produce those products. The workspace system provides a bulk processing facility for this purpose. The key ideas of this facility are:
- Processing is quality-assured
- Processing is estimable, visible and cancellable
- Processing utilizes large clusters for high throughput, such the local cluster or the public Open Science Grid
- Processing may be set up prior to the availability of input products, and will kick off when they arrive
- Processing options are edited by users and the provenance is tracked
The architecture presented here was developed using Attribute-Driven Design. The design iterations are available in the Design Iterations document.
The overall architecture here is that of a web application atop two services: a capability service and a lower-level workflow service that it uses.
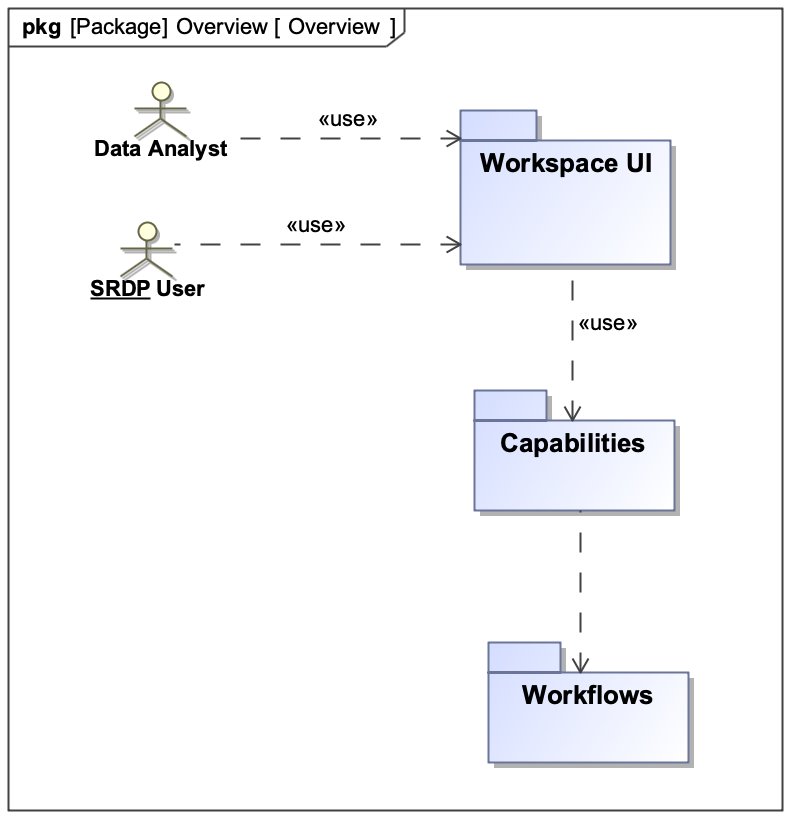
The workflow service provides lower level access to non-local computing in various clusters. Workflows are somewhat generic; they have their own inner structure of tasks and task dependencies, but they don’t explicitly know anything about science products or the other high-level concerns of scientists and NRAO staff. The capability service is higher-level, dealing with products explicitly, handling quality assurance, and handling parameters.
These two major services form packages, each built from smaller services:
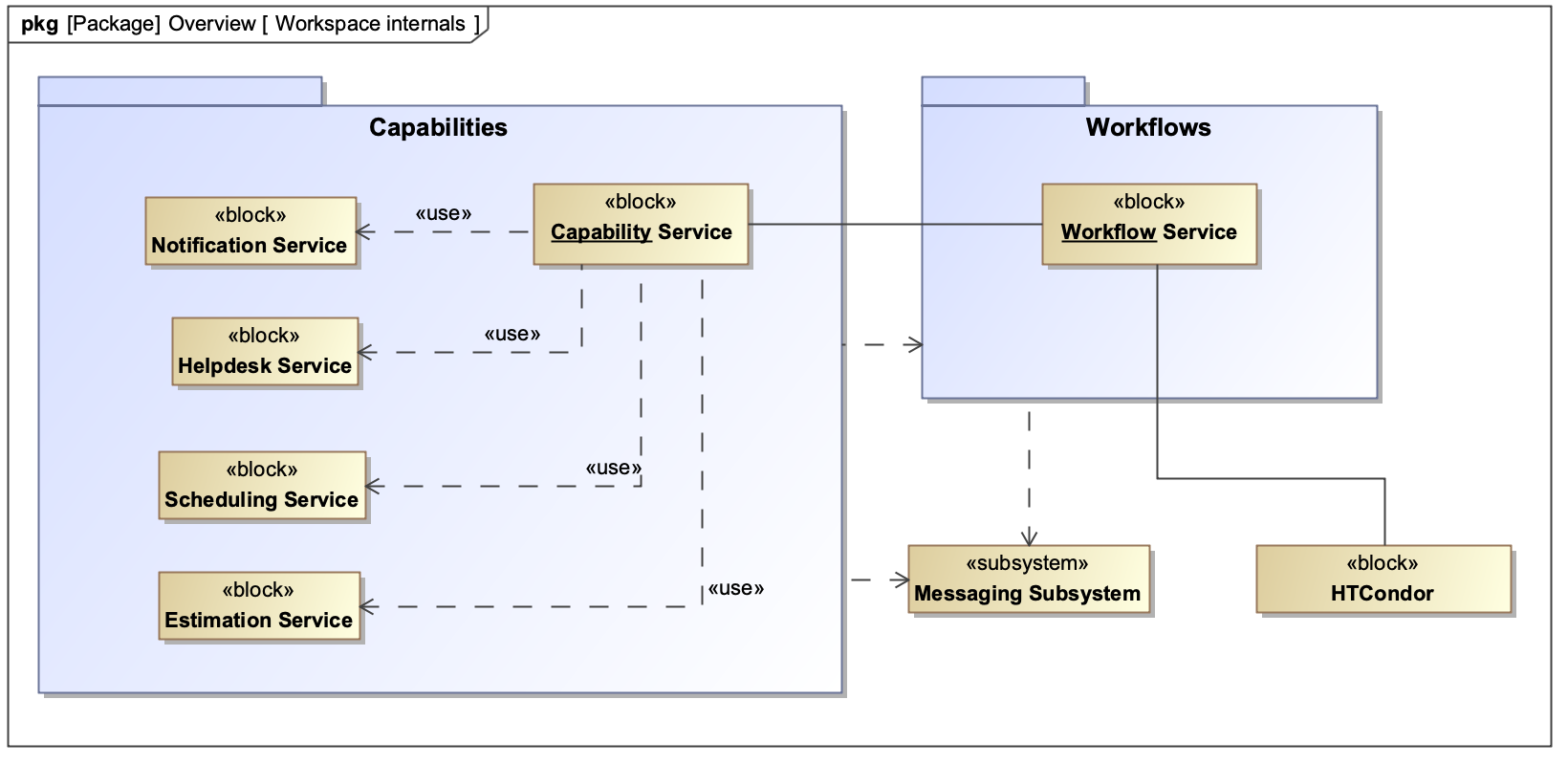
These services each have a simple role: the notification service sends email notifications to users, the help desk service facilitates creating, locating, closing and linking to science help desk tickets, the scheduling service allows us to perform actions routinely on a schedule, and the estimation service retains and publishes timing metrics for capabilities.
Alongside these services are several external systems: the archive (meaning the system which manages the NRAO archive), the authentication/authorization (A3) service, the science help desk, the messaging subsystem, HTCondor and the OpenScienceGrid. Processing is realized by making requests for capabilities.
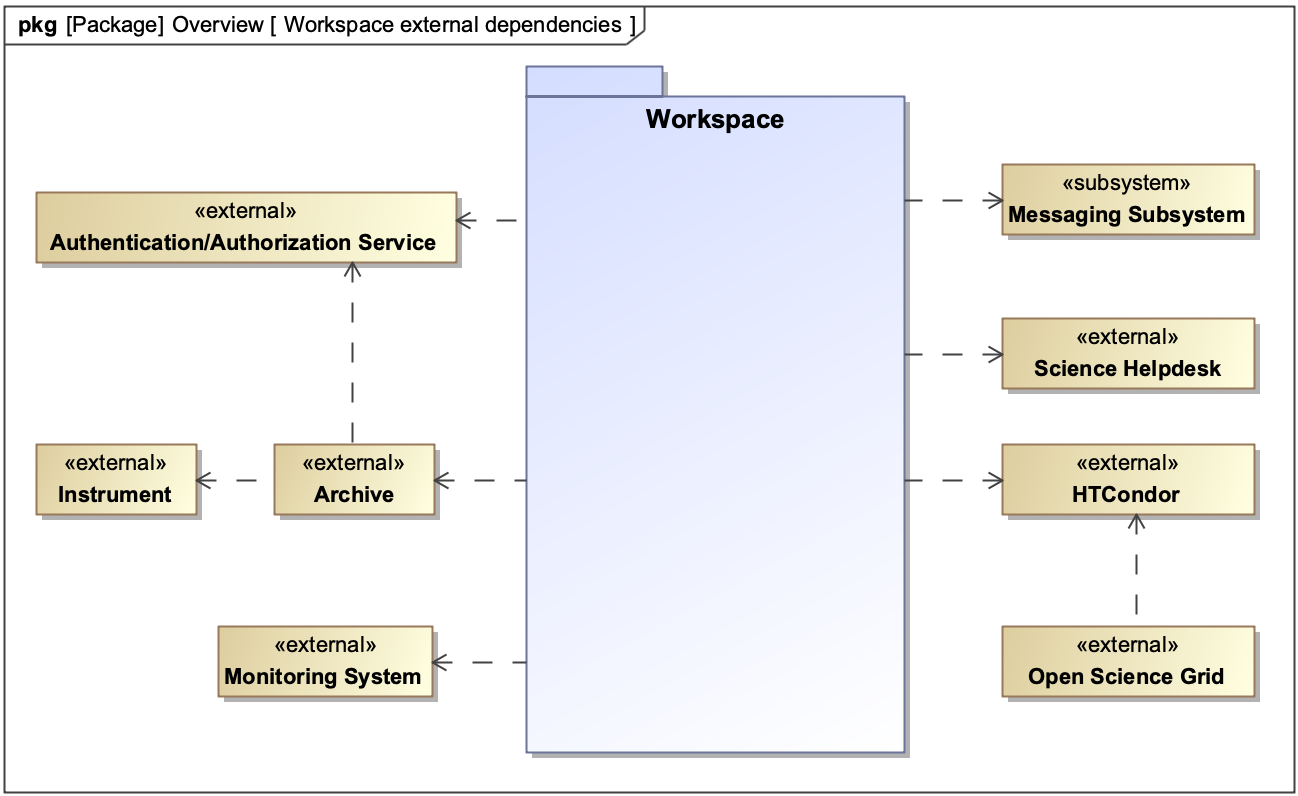
Within the system are several shared components that act as services internally but which are not exposed: the messaging subsystem (which is shared with the archive), the notification system, and the scheduling system. Additionally, there is the estimation system, which passively collects metrics data for analytics but also exposes an API for retrieving estimates of how long work will take.
Aside about user interfaces
I have left the workspace UI as a mostly blank box. Early on, we decided to leave the workspace UI underspecified for the sake of agility. We have interpreted requirements that explicitly mention user interaction as instead requiring functionality in the service layers which the UI can use to implement the requirements. For this reason, almost no actual work is allocated to the workspace UI. Instead the workspace UI is only mediating access to the user.
It is worth noting that the UI will necessarily break down into several sections based on their primary purpose and intended audience, as described by this diagram.
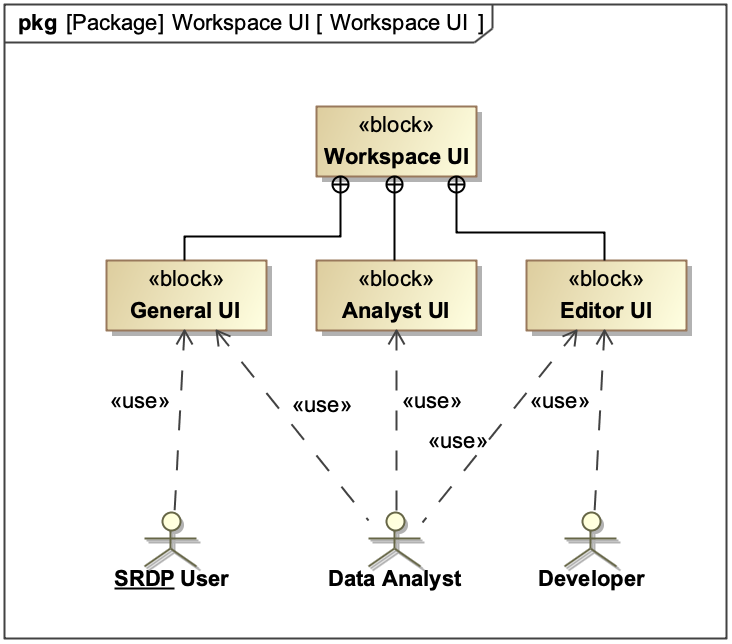
The editor interface will expose the create-edit-delete operations for capabilities and workflows, but otherwise goes unmentioned in the rest of the document.
It can be assumed that the workspace UI will eventually decompose into some code running in the browser backed by some code running on a web server. The nature of this breakdown is left unspecified for now, but is likely (leveraging the strengths of the SSA team) to be based on Angular 2.0 and Python. The web developers will iterate directly with stakeholders to build a useful UI using the components designed in this architecture.