-
 Nathan Hertz authoredNathan Hertz authored
Nathan Hertz authoredNathan Hertz authored
REST and AMQP, from Amygdala to Workspaces Rules Engine
Introduction
The archive and workspaces systems are heavy users of both REST and AMQP.
REST
REST stands for REpresentational State Transfer but in the relatively weak form we use it generally connotes services that are A) offered over HTTP, B) utilize the semantics of HTTP verbs (GET, PUT, DELETE especially), and C) leverage the semantics of HTTP response codes. In principle REST services may accept and provide various formats but in practice we tend to implement JSON only. REST services define a certain filesystem-like hierarchical structure, and it's common to think of that structure as defining collections of entities which contain other collections of other entities.
Because REST builds on HTTP, there is a synchronous request-response cycle; you send one request, you get one response, and then you can send another. Every request is paired with a single response, and in general those responses should return in a timely fashion. It's perfectly OK to transmit arbitrarily large content to and fro with HTTP.
AMQP
AMQP stands for Advanced Message Queuing Protocol and has a very different set of semantics from HTTP. AMQP defines several concepts: messages, which are opaque packets of bytes to the system; exchanges which are a place messages are sent, from which they are routed by the system to queues. We generally use "topic" exchanges, which are named and allow routing based on matching patterns in a key which is supplied along with the message. AMQP doesn't know or care about the structure of your messages, but we use JSON pervasively so that messages are easy to encode, decode and inspect. AMQP queues have an associated lifetime, which is either persistent forever or transient; transient queues disappear when the connection is closed but persistent queues continue to gather up messages even when no clients are there to receive them, a fact we leverage to great effect.
You'll notice there are no explicit request/response pairs in AMQP, and this is because once a connection is made to the AMQP server, the client can freely send and receive messages as its heart desires. It's perfectly normal for an AMQP client to open a connection and wait an indeterminate time for events to roll in.
Benefits and Drawbacks
The technical details of these protocols are interesting, but what is the high-level perspective on them? We use both for a reason, what's the reason?
| REST | AMQP | Comments | |
|---|---|---|---|
| Sync/Async | Synchronous | Asynchronous | AMQP is better for fire-and-forget messages, REST is better for RPC-like acknowledged messages. AMQP individual message overhead is very low compared to REST. Emulating synchronousness with AMQP requires sending overt reply messages. |
| Size Limit | No | Yes | While technically feasible, large messages are extremely inefficient in AMQP. REST is fine with gigabyte-sized files |
| Message Overhead | High | Low | AMQP nicely handles extremely high volumes of messages. REST is better suited to much lower volumes. |
| Ease of Access | Trivial | Support library needed, not accessible from the browser | Browsers can only make HTTP connections, so to access AMQP over the web, you need a gateway of some kind. HTTP is well-supported by essentially every language. |
| Coupling | High | Low | Systems that interconnect with REST must call each other directly. AMQP allows pu blish-subscribe topologies in which the communicating parties do not know each other and have no overt connection to each other. |
This table helps to sort of partition the messaging space into two:
REST is preferred when...
- Browsers must communicate with the service
- Service has a synchronous character, where a reply is expected within a short, finite amount of time
- Large content needs to be exchanged
AMQP is preferred when...
- Message has an "FYI" quality, not really intended for one particular consumer
- Messages are small but message volume is high
- Message persistence is desired
- Distributed processing with many workers is needed (round-robin access to queue)
Changes from the Archive
There is one notable change in behavior between the archive and workspaces, and this is that workflows are initiated by REST calls in Workspaces versus AMQP messages in the archive.
In terms of the benefits and costs, AMQP is hardly warranted in this scenario as workflow initiations are infrequent. A possible benefit here is the queuing up of workflow requests, but in practice we haven't seen a lot of benefit here, workflow downtime is less of a problem than workflow resumption after a restart, which was a design goal.
If it isn't possible to initiate a workflow via a REST call, how do users cause workflows to get executed in the archive? The answer is that the ALMA RH (request handler) has been modified to send workflow start messages. There is a failure mode in which the workflow server is offline but the RH is still able to queue up workflow requests, which is a functionality lost in the workspaces system. In the fullness of time, Workspaces replaces the RH and there is a scenario there where the capability or workflow service is offline and you're consequently unable to submit a workflow. I would argue that this may be an improvement over the current system, in that we have had several bugs reported because a workflow server was offline and requests were sent but appeared to go nowhere.
Amygdala
Concept
It seems obvious, but if you want to decouple two systems, it's important that they not know too much about each other. For this reason, I don't want the archive to tell the workspaces system "run a calibration on this raw data" when instead it could say "we have received an observation"—which is a general purpose message that could have many interested parties that want to receive it—and have some other system concentrate the intelligence of knowing that receiving observations means we need to run calibrations.
In general we group these into a few different categories of messaging "intelligence":
-
Protocol changes: resending messages over AMQP that arrived via other channelsE.g.: MCAF and the CBE use webhooks and UDP broadcast to notify other systems that files have been generated.
-
Level changes: converting a message about a child into a message for its parentE.g.: a workflow status message is translated into a capability status message to protect capability consumers from knowing too much about workflows
-
Semantic changes: converting a semantically vague message into a specific oneE.g.: an ingestion-complete message for a new observation necessitates a message that it is time to calibrate this observation
There is a system in the archive that does this, called "amygdala." The name amygdala was chosen because this is analogous to what your brain stem does, it receives electrical signals from your nervous system and reacts to them by sending other electrical signals. I also wanted to make it clear that it should not be all that smart, we'd need a more powerful system for more complex rules as time went on.
Time went on and now we have a more complex design, which is Workspaces.
Rules engine
Towards the end of the design phase we determined we'd need to have a primitive "rules engine," which would have a simple pattern/action design, and we left it kind of vague. There's a sketch of an initial design in Cameo which looks like this:
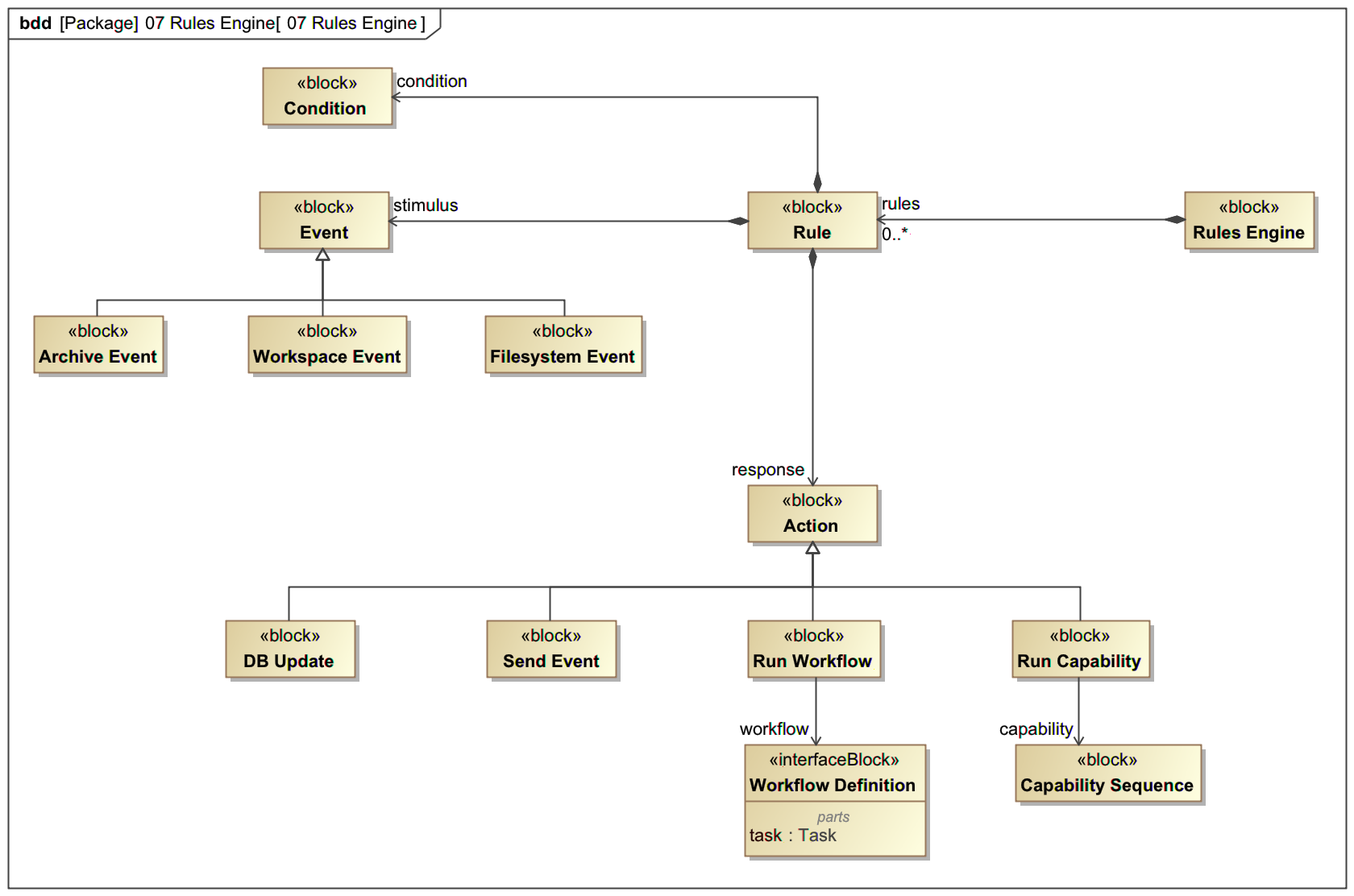
As you can see, the concept in the rules engine is that we have some number of rules, each of which is looking for a certain type of event, matching some sort of condition on it, and then responding in a few pluggable ways. I imagine a tabular representation for the rules that looks something like this:
| Event | Condition | Response | Commentary |
|---|---|---|---|
| Filesystem Event | new file in /foo | Send Event new-file | A protocol change rule, converting a filesystem event into an AMQP event |
| Workspace Event | message type = w orkflow-status and capability_id is defined | Send Event cap ability-status | A level change rule, converting a workflow (hidden) into a capability event |
| Archive Event | message type = inge stion-complete and instrument = VLA | Run Capability standa rd-calibration | A semantic rule, this is the CIPL-portion of amygdala. Implemented by sending a REST call to the Workspaces capability service |
I'm prepared to remove the Run Workflow and DB Update actions, but I think it's good to have an extensible response/action interface and they're decent illustrations.
This is newer than the discussion in the Workspaces architecture overview which simply says that amygdala will need to be modified to initiate capability requests instead of workflow-start events.
Who owns amygdala?
Data and processing are really two sides of the same coin. You can't have processing without data to process; you can't really have two related pieces of data without the processing that took one and transformed it into the other. So some rules look like they clearly belong to the archive and some look like they belong to workspaces. I allege that this is just because the two systems collaborate a lot, since workspaces does all the processing for the archive, and the archive keeps all the data for workspaces to process. Eventually the two systems have to live together.
I allege that the rules engine here has to have some knowledge of both these systems and could live in either one. A decision simply has to be made which, and the code in amygdala needs to be converted into this rule format and made data.
Decision
- We should replace amygdala with this rules engine
- It doesn't matter whether that's in workspaces or the archive because eventually the projects come together
- Before taking it to production, we need to make sure that it either shares responsibility with amygdala properly or amygdala's functionality is replaced with it and amygdala is removed